M-P神经元and感知机
M-P神经元模型
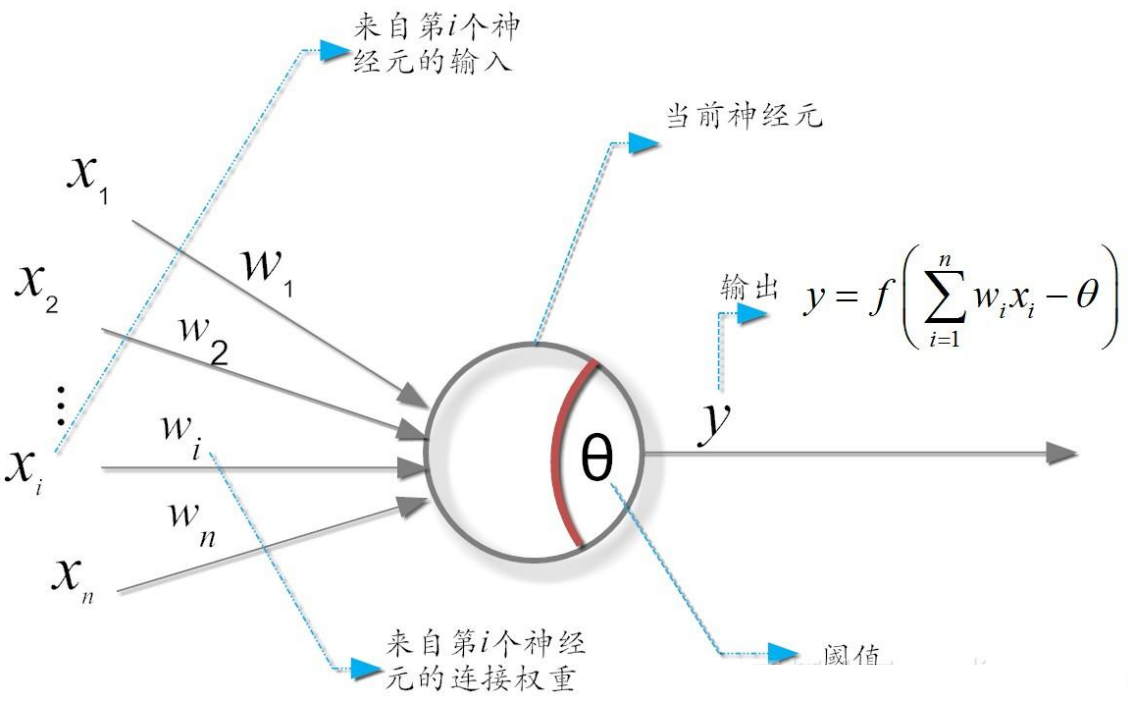
代表传入信号
代表权重
大脑🧠神经元的状态:兴奋和抑制 分别利用 1 和 0 来进行表示
通过这样的二进制的机制来模拟大脑工作
的大小来模拟神经元的重要程度?就是一个权重,好比一个公司的股份,你股份越大你越有话语权的意思
神经元激活与否取决于阈值(threshold) ,只有输入的信息经过处理后超过了阈值 才会激活神经元,否则神经元不会输出信号,即:
这个时候才会被激活
而的输出,只有1和0,即兴奋或者是抑制
激活函数
常用激活函数分为线性函数和非线性函数

S型的函数在梯度下降的时候会再提
总结📜🖋
每一个神经元都是一个多输入单输出的处理单元
神经元的输入分为兴奋(1)和抑制(0)
感知机
感知机被称为最简单的神经网络
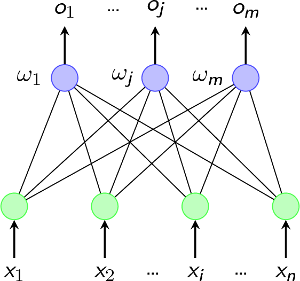
它是由两层神经元构成的神经网络,即输入层和输出层
输入层接受外界输入的信息,经过激活函数(含阈值)的变换,最后把信号传送到输出层
感知机是有监督的学习,所有的有监督学习,在某种程度上都是分类学习算法
| 品类 | 颜色() | 形状() |
|---|---|---|
| 西瓜 | 1(绿色) | 1(圆形) |
| 香蕉 | -1(黄色) | -1(弯形) |
所以:
西瓜:.
香蕉:.
所以由激活函数得到
2————>1
-2————>0
这样就区分出了西瓜和香蕉
但是我们这里是默认了的值,但是它其实并不都是1,这就是权重,所占的比重大小
而这个比重,就是经过反复的训练(试错)得出来的比重,比如说区分男生和女生
头发长短的比重是1,有无喉结所占比重是9,那么头发长度只占有10%的比重,而这个比重是不足以进行下定结论的
就好比如,一个长头发的男生,他是长头发,但是他由喉结,所以
.
感知机的学习过程
因为“知错”,就表明它事先有了事物的评判标准,如果它并不是目标物,就会有个偏移量用来纠正
神经网络的学习规则,就是调整权重和阈值的规则假设规则是:
.
.
其中,是期望输出,是实际输出,所以实际上就是一个偏移量
感知机的学习过程就是一个纠偏的过程,把权重纠正到能够满足需求的过程
比如我们将刚刚的,阈值依然为0
那么,这个时候我们计算西瓜
西瓜:.
经过激活函数处理0————>0,这个时候已经判断出错了,既然判断为香蕉,感知机知道与原来输入的标签不符,所以进行纠正偏差
这个时候本应该正确的判定期望输出,而实际输出,所以就需要纠正偏差
将代入:
经过纠偏以后,再输入西瓜的信息:
.
这样,经过学习以后,就判断正确了
然后再反复输入西瓜和香蕉,知道就代表网络已经稳定,学习结束
感知机训练法则
假设阶跃函数.
它即可完成常见的逻辑运算
1、逻辑“与”运算()
令时有:
此时,当且仅当时(都为真),&&\ y = 1&&(为真),其他情况下都为假,即无论还是为0,那么恒成立
这样就完成了逻辑”与”运算
2、逻辑“或”运算()
令时有:
此时,当或中有一个1,那么就为真,即&&\ y = 1&&,和都为0时,就为假
3、逻辑“非”运算
令时有:
这时,当时,,反之则相反
但是它莫有办法实现“异或”逻辑运算
一般的,我们给定大量的数据,神经网络的和都可以通过纠偏学习得到
感知机的学习规则可以更加简单
对于训练样本,若当前感知机的实际输出,假设不符合预期,存在偏差,那么感知机的权重规则调整为:
其中,称为学习率(learning_rate)
注意:
学习率η的作用是“缓和”每一步权值调整强度的,它本身的大小,也是比较难以确定的。
如果太小,网络调参的次数就太多,从而收敛很慢。
如果太大,从而错过了网络的参数的最优解。
因此,合适的大小,在某种程度上,还依赖于人工经验(即属于超参数范畴)。通常,将的初始设置为一个较小的值(如0.1)
多层感知机
简单的两层神经网络的感知机没办法完成“异或”的逻辑运算
因为复杂的逻辑运算,单单两层的感知机是没办法完成的,那就来多层
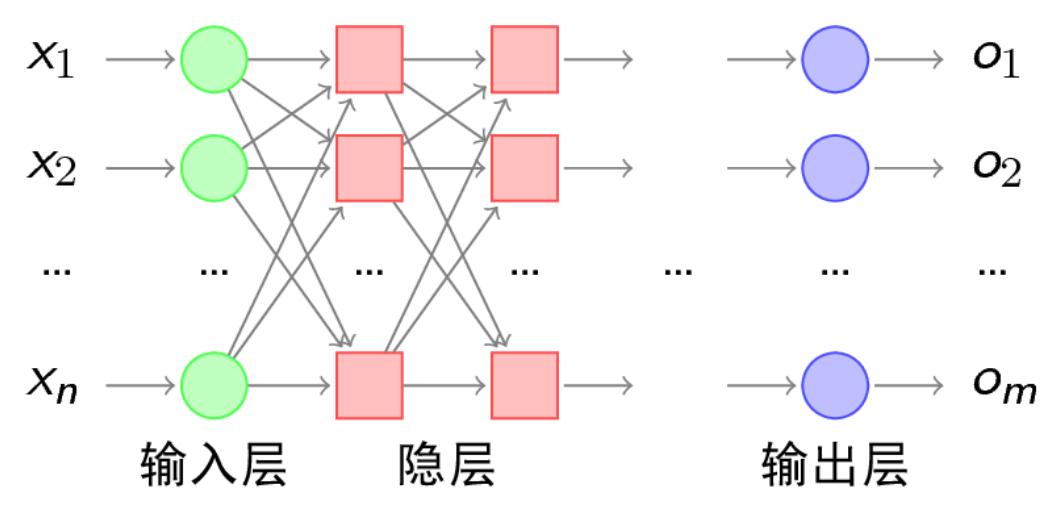
再输入层和输出层之间的我们称为隐含层
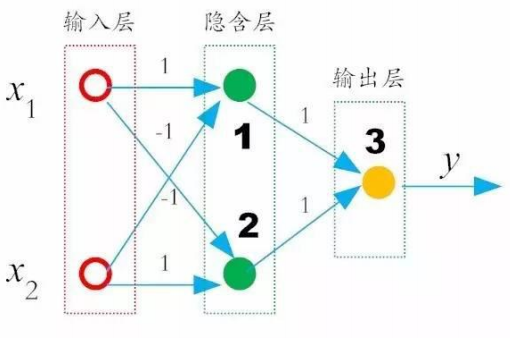
在我们刚刚的人工神经网络中添加一层隐含层
令,并且对隐含层节点1和2的权重分别为,对隐含层节点1和2的权重分别为,那么:
隐含层节点1:
所以此时,当时,输出,满足异或
当时,输出,满足异或
对于和不相同时,假设时
隐含层节点1:
这样当和不相同时,,就满足异或功能了
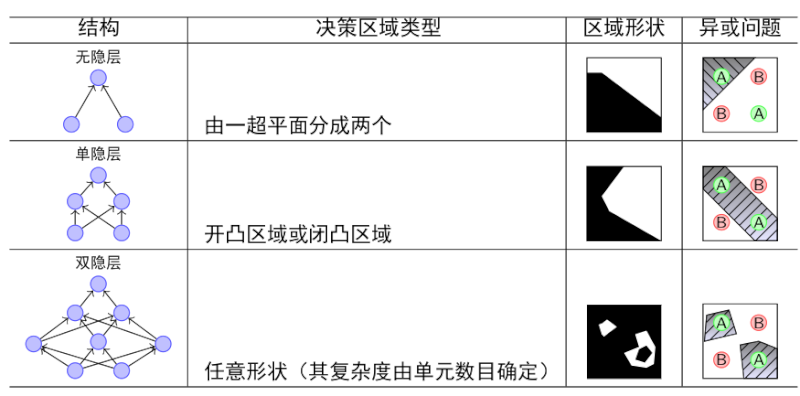
从上图可知,双隐层的感知机可以解决所有的复杂问题了,但是,问题是它每个神经元节点的权重怎么训练到最佳值?
这个时候就迎来了ANN低潮期
而后就有了BP神经网络

