BP神经网络
简介
误差反向传播算法简称反向传播算法(即BP算法)。
使用反向传播算法的多层感知器又称为BP神经网络。BP算法是一个迭代算法,它的基本思想为:
1、先计算每一层的状态和激活值,直到最后一层(前向传播)
2、计算每一层的误差,误差的计算过程是从最后一层向前推进的
3、更新参数(目标是误差变小)。迭代前面两个步骤,直到满足停止准则(比如相邻两次迭代的误差的差别很小)
本文约定
对于M-P神经元和感知机(简单的前馈神经网络)都在上一篇博文中介绍了,现在先规定一下下面讲解推到过程的时候的一些记号
表示第层的神经元个数
表示神经元的激活函数(激活函数我另外会再开一篇博文来记录)
表示第 层到第 层的权重矩阵
表示第层的第个神经元与上一个,即层的第个神经元的连接权重
表示第层的第个神经元的偏置
表示第层到第层的偏置
表示第层中第个神经元节点的输入值
表示第层到第层的输入
表示第层中第个神经元节点的激活值(输出值)
使用的图片来源网络,部分符号约定不同自行变通
本文以三层感知机为例
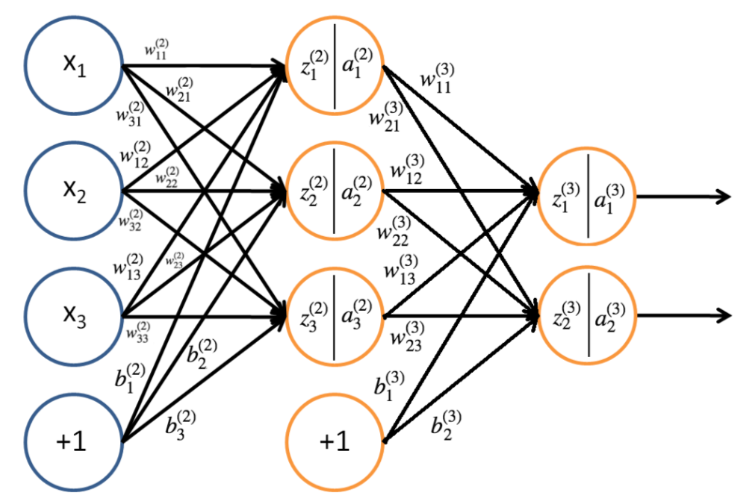
信息前向传播
由该神经网络可以得出第二层的参数
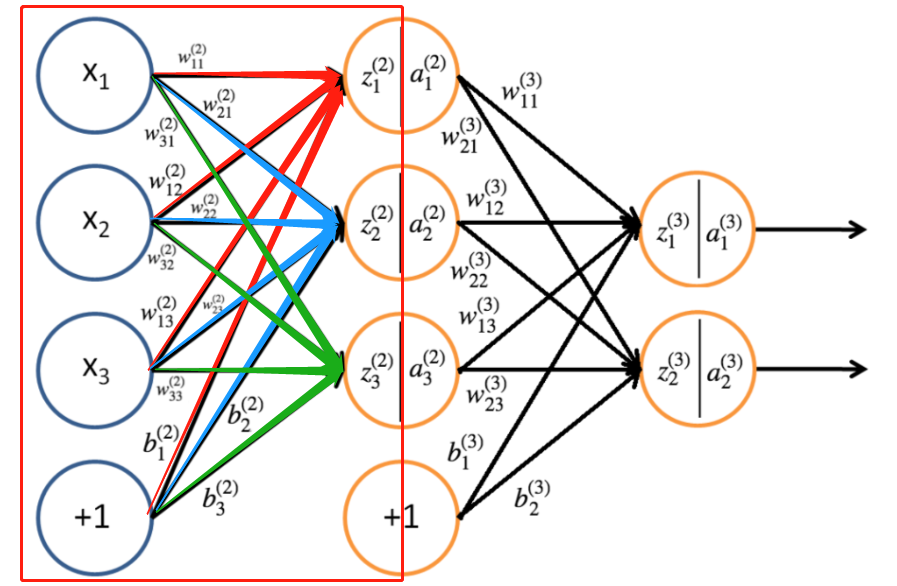
并且,我们能够用相同的方法计算第三层的参数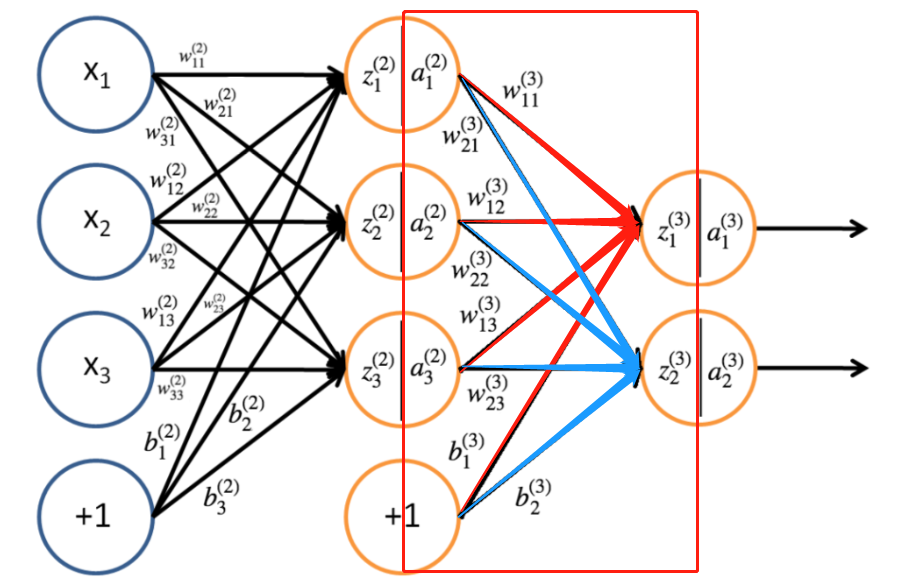
所以可以总结出,第 层神经元的输入和激活值(输出值)
所以对于前馈神经网络的信息前向传播的传递过程入下:
误差反向传播
目的:调整权重和偏置直到最优,知道损失函数最小为止
使用方法:梯度下降法(本文使用批量梯度下降、随机梯度下降)
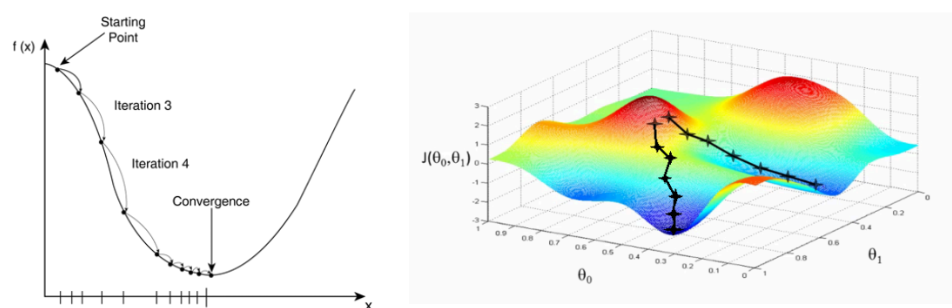
权重和偏置的更新规则为:
表示该连接的新权重和旧的权重
表示该连接的新偏置和旧的偏置
表示每个 数据计算出的损失函数的平均
代表学习率,即“步长”
下面我们求损失函数(本文使用平均损失,交叉熵损失函数暂无)
对于训练数据为即总共由组训练数据(不含测试数据),所以它最后的输出的训练实际值就有
对于某一个数训练数据来说就有一个损失函数:
代表期望的输出,也就是我们自己给出的数据中的值
为网络的实际输出
所以一个epoch下来,的平均损失:
输出层权重更新
还是用本文前那个神经网络进行示例进行输出层权重的更新
$\ J_{(3)} = \frac{1}{2}\parallel y^{(3)}-o^{(3)}\parallel \\ \qquad = \frac{1}{2}\parallel y^{(3)}-a^{(3)}\parallel \\ \qquad =\frac{1}{2}\left [(y^{(3)}_1-a^{(3)}_1)^2+(y^{(3)}_2-a^{(3)}_1)^2 \right ] \\ \qquad =\frac{1}{2}\left \{\left [y^{(3)}_1-f(z^{(3)}_1)\right]^2+\left [y^{(3)}_2-f(z^{(3)}_2)\right]^2\right \} \\ \qquad =\frac{1}{2}\left \{\left [y^{(3)}_1-f(w^{3}_{11}a^{(2)}_1 + w^{3}_{21}a^{(2)}_2 + w^{3}_{31}a^{(2)}_3 + b^{(3)}_1)\right]^2+\left [y^{(3)}_2-f(w^{3}_{12}a^{(2)}_1 + w^{3}_{22}a^{(2)}_2 + w^{3}_{32}a^{(2)}_3 + b^{(3)}_2)\right]^2\right \} $由链式求导法则去分别对求偏导
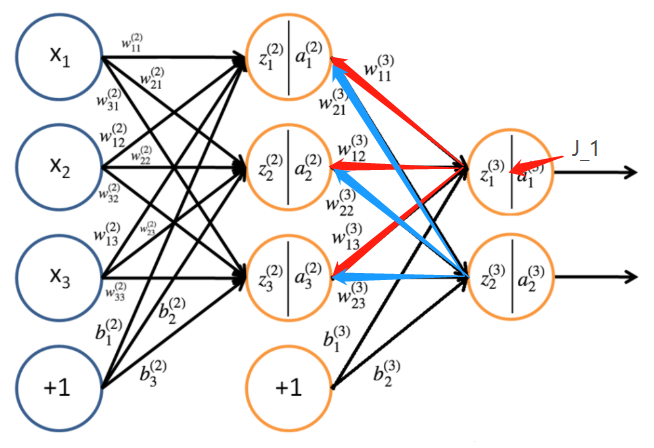
再拿为例,带入求偏导得:
根据上面的公式,我们令:
所以:
所以,假设神经网络一共由层,那么对一般式而言:
对向量/矩阵运算:
再用这个式子进行权重的更新即可
隐藏层权重更新
隐藏层的权重更新也是使用链式法则求偏导数,只不过平时使用的都是向量而已:
对更新:
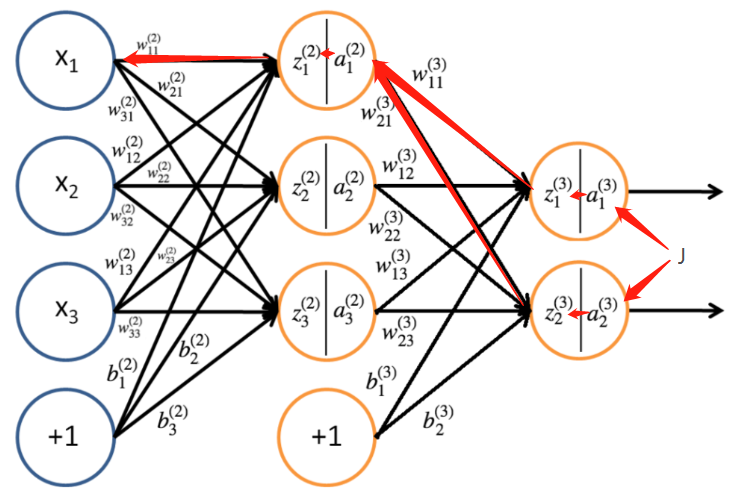
再结合
其他隐藏层权重更新同理,在这里不再过多赘述
接着使用刚刚我们定义的推导公式
当在隐藏层时,又链式法则和函数和求导公式就有:
所以
$$\ \delta^{(l)}_i = \frac{\partial J}{\partial z^{(l)}_i}=\sum^{n_l+1}_{j=1}\frac{\partial J}{\partial z^{(l+1)}_j}\frac{\partial z^{l+1}_j}{\partial z^{l}_i}=\sum^{n_l+1}_{j=1}\delta^{(l+1)}_j\frac{\partial z^{l+1}_j}{\partial z^{l}_i} $$又因为
所以有:
再带入前面的:
$$\ \delta^{(l)}_i = f'(z^{(l)}_i)\sum^{n_l+1}_{j=1}\delta^{(l+1)}_{j}w^{(l+1)}_{ji} $$ 对向量/矩阵运算: $$\ \delta^{(l)}_i = f'(z^{(l)}_i)\odot (W^{(l+1)})^T\delta^{(l+1)} $$输出层偏置更新
偏置的更新其实和权重更新是一样的
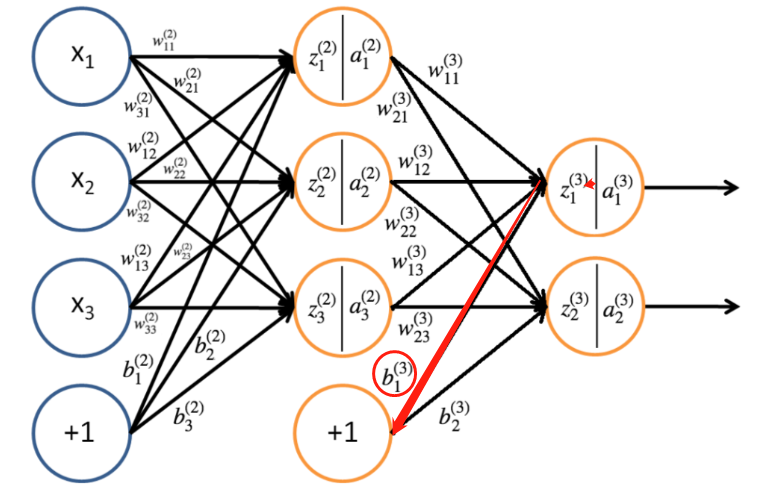
输出层的偏置比较好算
再结合
隐藏层偏执更新
隐藏层偏置更新和权重更新也是一个道理
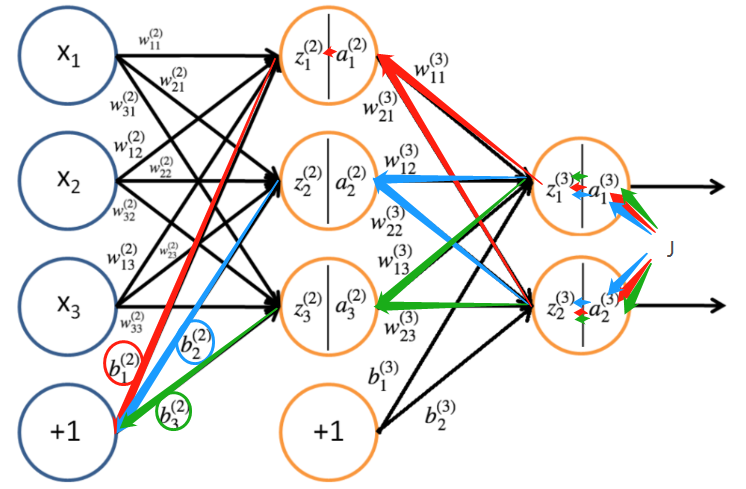
再根据对权重的推论,同理可得:
$$\ \delta^{(l)}_i = \frac{\partial J}{\partial b^{(l)}_i}=\frac{\partial J}{\partial z^{(l)}_i}\frac{\partial z^{(l)}_i}{b^{(l)}_i} $$ 对向量/矩阵运算: $$\ \delta^{l}=\bigtriangledown_b^{(l)}J $$再结合:

